DATA SCIENCE И BUSINESS INTELLIGENCE В ДЕЙСТВИИ

Каждый маркетолог знает, что сегментация целевой аудитории – наше все!
Сегментация ЦА позволяет лучше узнать своих потребителей, более точно формировать рекламный посыл для каждого сегмента, а также правильно формировать продуктовую линейку. Это приводит к более полному и качественному удовлетворению потребностей покупателей, и в итоге к увеличению продаж и прибыли.
Сегодня хотим рассказать вам об одном интересном кейсе сегментации - о сегментации покупательских корзин.
Для анализа возьмем данные одного из наших клиентов, а именно информацию из чеков за один месяц одного магазина торговой сети алкомаркетов. Клиент любезно разрешил нам использовать его обезличенные данные для научной публикации. Один чек – это фактически одна покупательская корзина.
Алкомаркет мы взяли с той мыслью, что там не слишком широкая ассортиментная линейка, и каждая группа покупателей из-за этого более четко выражена и интуитивно понятна. Тем самым, на нем хорошо приводить примеры (см. ниже).
Сами по себе данные, которые содержаться в чеках, являются бездонным кладезем полезной информации. Их можно анализировать бессчетным количеством разных методов.
Итак, мы взяли чеки за один месяц и специальным математическим алгоритмом сгруппировал их по похожести продуктового набора и количества товаров. Группировка и поиск похожести проводилась не по отдельным SKU, а по товарным группам.
В итоге мы выявили несколько групп потребителей (в нашем случае их было 5) с одинаковым покупательским поведением, потребностями и привычками. Ну что же может быть прекрасней! Сегментация в действии.
Для визуализации результатов нашей сегментации мы использовали так называемую лепестковую диаграмму. Этот тип графика еще называется «Radar Chart» или «паутинка». Эту диаграмму удобно использовать для сравнения между собой многопараметрических объектов. У нас этому типу визуализации посвящена отдельная статья.
Вот как выглядят результаты работы нашего алгоритма в табличном виде (таблица представлена в урезанном виде):
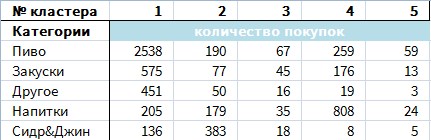
А вот наша лепестковая диаграмма, построенная на данных из таблицы выше:

Если вы раньше не встречались с таким типом графиков, то он вначале может вам показаться немного сложным. Но если вы к нему привыкнете и поймете структуру, то он позволит вам понять всю ситуацию в целом за один лишь взгляд.
Каждый покупательский кластер обозначен своим цветом. По осям каждой категории товара отложено количество покупок за месяц в данной категории в данном кластере. Центр - ноль покупок. Чем ближе график к краю круга, тем больше совершено покупок в данной товарной категории людьми из данного кластера, тем соответствующие предпочтения сильнее.
Этот график, где одновременно изображены все 5 групп покупателей, хорошо показывает, насколько эти группы разные в своих предпочтениях!
Давайте посмотрим каждый кластер по отдельности и попробуем понять, что из себя представляет каждая группа покупателей. Еще раз - чем ближе график к краю круга по направлению определенной категории, тем больше товаров из этой категории покупают люди из данного кластера.
Кластер №1
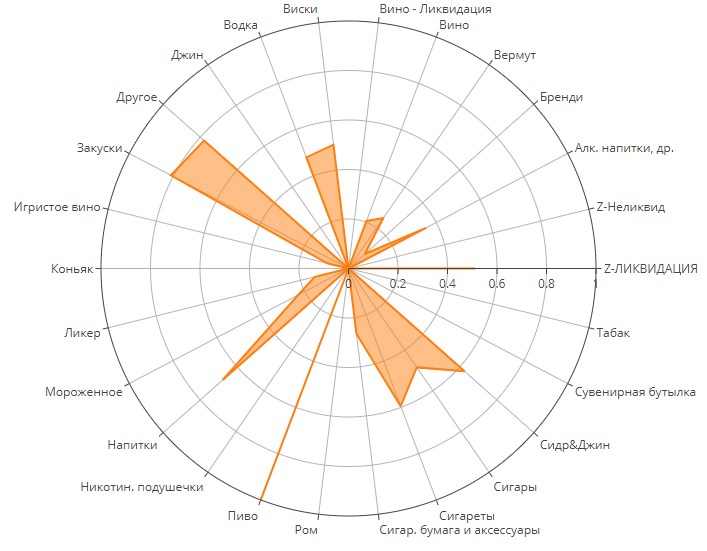
Абсолютный лидер покупательских корзин людей из этого кластера - пиво. Потом идут закуски. Пиво-чипсы-орешки. Тут все понятно. Т.н. пивозавры. Иногда покупают в комплекте также водку, видимо, чтобы «ускориться».
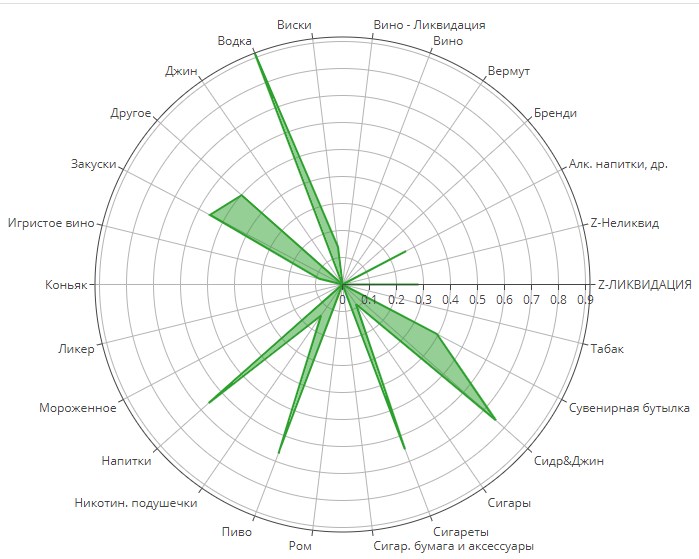
Кластер №2
Абсолютный лидер водка. На втором месте сидр/джин, пиво, напитки. Видимо для «запить». Закуски тоже используются, но гораздо реже, чем вместе с пивом (см. общий график).
Группа также абсолютно понятна и прозрачна. В дополнительных объяснениях не нуждается.
Кластер №3
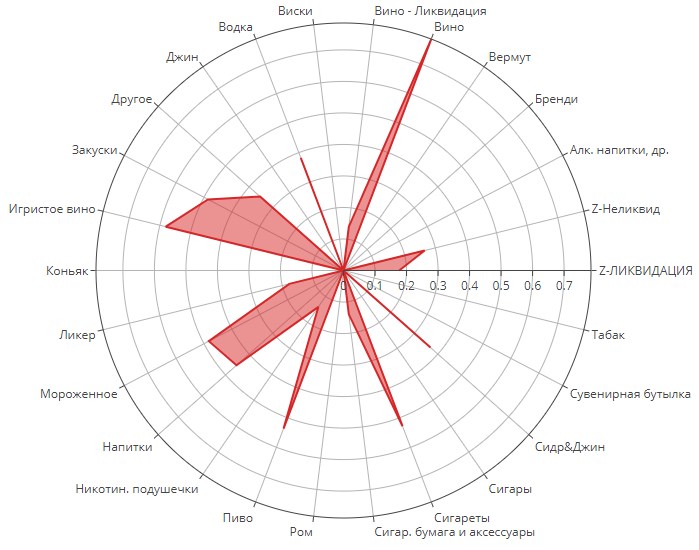
В корзинах этой группы доминирует вино. В меньшей степени также могут присутствовать более легкие напитки - шампанское, пиво и, внимание, мороженное! Также есть небольшой акцент на товары из распродажи. Мороженное и шампанское нам подсказывают, что это кластер женский. Уцененные товары, возможно, показывают на молодых девушек, может даже студенток, которые любят «винчик», но денег на дорогие сорта у них нет.
Кластер №4
Этот кластер можно назвать «заскочили за сигаретами». Как мы видели выше, сигареты появляются регулярно и в других корзинах, но там они идут в нагрузку к другим товарам. А здесь целью визита в магазин являются именно сигареты, и иногда какие-то другие напитки, преимущественно безалкогольные! Т.е. - «Пачку сигарет. И водичку какую-то дайте».
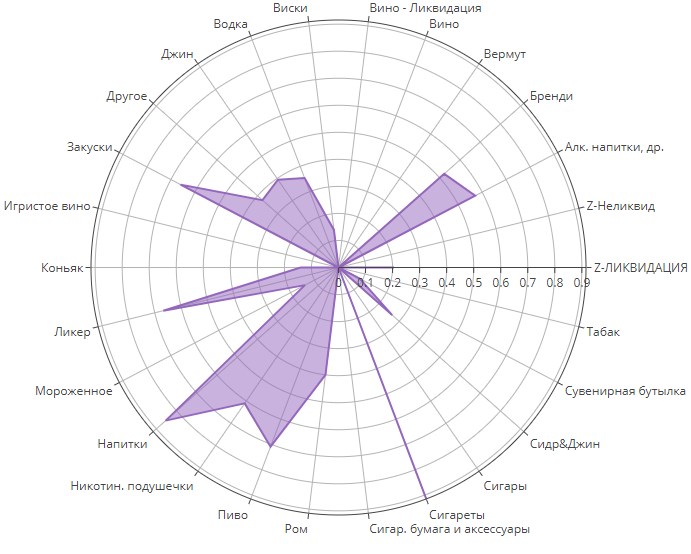
Кластер №5
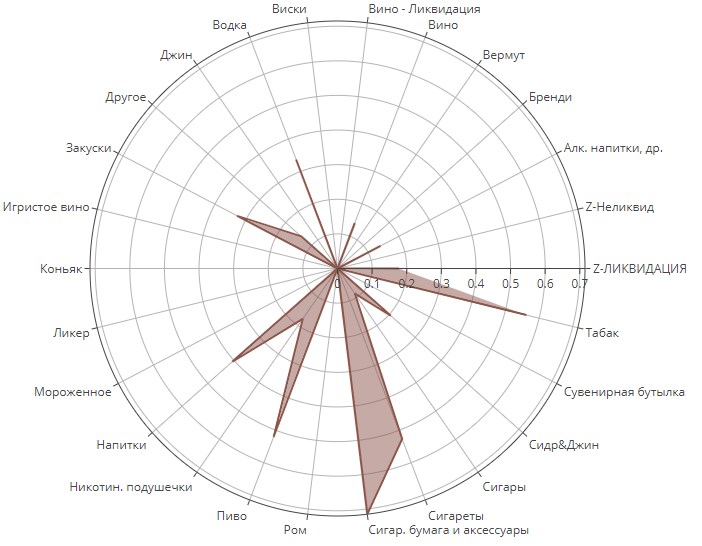
Видим совершенно особенный кластер. Это люди любители «кастомного» курения. Они специально приходят, чтобы купить только табак и бумагу, чтобы крутить самокрутки. Иногда могут прихватить с собой пару пива.
Осталось понять, какой процент от общего количества покупателей занимает каждый кластер. Построим для этого круговую диаграмму.
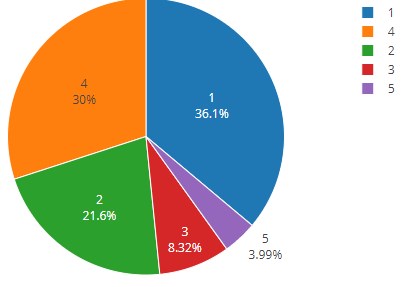
Соотношение довольно ожидаемое. На первом месте люди, которые приходят за пивом, на втором месте «заскочили за сигаретами», на третьем месте любители водки. Женщины и любители самокруток сильно отстают, и занимают, соответственно, четвертое и пятое места.
Сделаем выводы. Даже после такого довольно грубого и неполного анализа мы видим, что у рассматриваемого магазина большие проблемы. Покупательские корзины очень «узкие». Руководству сети и магазина необходимо принять целый ряд мер, который бы расширил ассортимент одной корзины. Также важно будет расширять аудиторию. Например, привлечь к себе покупателей вин средних и высоких ценовых категорий. Увеличить количество спонтанных покупок (себе пиво, детям чупа-чупс). Возможно подумать об увеличении предложений продуктов повседневного спроса – хлеба, ЗПФ, яиц. В общем есть о чем поразмыслить.
Очевидно, что данный вид анализа, хоть и очень информативный, не является исчерпывающим. Для получения более полной картины, можно провести и другие исследования. Средний чек, динамика средних чеков, распределение чеков, частотность покупок, динамика товарооборота, распределение SKU внутри групп, бестселлеры, привязка покупок ко времени, АВС и XYZ анализ, факторный анализ прибыли/убытков, географическое распределение эффективности магазинов и т.д. и т.п. Также важен анализ объемов тары и ценовых категорий. И это далеко не полный перечень.
Например, покупка водки в 9 утра, чекушка в обед, и бутылка Finlandia в 9 вечера – это три совершенно разные водки, совершенно разные модели покупательского поведения.
Все эти исследования, вместе или по отдельности, могу помочь в принятии правильных управленческих решений, и в итоге вывести бизнес на новый уровень.
Это и есть суть бизнес аналитики, или как ее еще называют BI (Business Intelligence).
В дополнение хочется сказать, что в приведенном анализе мы не использовали данные карт лояльности (привязку корзины к конкретному покупателю). Также не учитывалось время покупки, и еще целый ряд других важных параметров. Но видим, что неплохие результаты получены даже без этих данных. Если же вдобавок использовать привязку к картам, а также имеющийся соцдем и другие фичи, то портрет корзин и групп покупателей будет просто прецизионно точным.
Если хотите подобный анализ, или любой другой анализ других данных, или может даже интерактивный дашборд с вашими данными (например, о продажах), обновляющийся в реальном режиме времени, пишите:
Немного подробнее о методе. Для тех, кому интересно
Математический алгоритм, который мы применяли для сегментации чеков называется кластерный анализ.
Мы написали отдельную статью про кластерный анализ на примере абстрактного магазина, где продаются только соленые огурцы и молоко "О кластеризации. Для маркетологов и категорийщиков. Объясняем на пальцах (огурцах)". Там мы простым языком, без математики, попытались рассказать о методе людям, которые не знакомы с математическим моделированием и машинным обучением.
Примечание 1. Для тех, кто помнит математику и для коллег аналитиков данных уточняем, что шкала на наших графиках логарифмическая и нормированная от 0 до 1. Если вы не знаете, что это, не переживайте, общий смысл от этого не изменится. Если строить графики на абсолютных данных, то пики (пивные, водочные) был бы значительно больше, а второстепенные товары сливались бы с нулем. Из-за этого визуально их оценивать и анализировать было бы гораздо труднее.
Примечание 2. Чрезмерное употребление алкоголя вредит вашему здоровью.
